
Cet article (très long, je vous le concède, mais sans IA) a pour vocation de vous donner un maximum d’éléments pour réaliser un audit technique SEO.
Vous ou une connaissance s’est peut-être déjà posé la simple question “Est-ce que mon site est bien niveau SEO ?” Pas si simple de répondre à cette question.
Un audit, quel qu’il soit, demande du temps et de la précision. Vous ne pouvez pas regarder un site en 5 minutes puis donner un avis professionnel et pertinent.
Vous risquerez d’avoir un rendu qui ne sera pas juste. Un rendu avec des manquements, des erreurs et une somme de recommandations qui ne sera pas pertinente face à la complexité de l’optimisation d’un site et de ses pages.
Dans cet article, nous allons lister et détailler les points les plus importants d’un audit technique et non pas d’un audit sémantique SEO (un audit sémantique est encore un autre travail).
Message perso : cet article est tiré en grande partie de mes expériences, si vous avez des désaccords sur certains points n’hésitez pas à me le communiquer mais en restant courtois svp 🙂
1 – Pourquoi faire un audit technique SEO ?
Les critères pour espérer être en première position sur une recherche Google sont très nombreux. Nous pouvons facilement en dénombrer plus de 200. Chacun avec une importance et un impact variable pour obtenir le site le plus performant imaginable.
Quand je parle de performance d’un site, dans le cadre d’un audit technique, je parle aussi bien des performances pour le ranking et l’indexation que des performances pour les visiteurs.
Cet audit technique va vous permettre d’avoir une photographie d’un site à un instant T. Cette photographie va vous permettre de connaître les bons et les mauvais points du site en audit. Le but est de préserver les bons points et d’optimiser au mieux les moins bons.
Cet audit sera la base pour la création de votre stratégie de référencement mais également la base pour atteindre vos objectifs.
Si vous êtes en train de lire ces lignes, vous souhaitez connaître un maximum des critères qui ont un impact sur le référencement et l’indexation de votre site. Alors commençons dès maintenant !
2 – Les questions à se poser en amont
La bonne réalisation d’un audit technique SEO nécessite de se poser quelques questions avant de vous lancer. Plus vous répondrez par “Oui” à ces questions plus votre audit sera complet.
- Ai-je les accès du site et de l’hébergement ? ✅
Les accès du site permettent d’aller plus en profondeur dans la structure du site, des pages et des contenus pour mieux comprendre ce qui a été fait.
L’hébergement du site va permettre de faire des modifications pour optimiser la vitesse du site et de certaines limites.
- Ai-je le nom et le plan du CMS utilisé ? ✅
En fonction du CMS du site vous aurez plus ou moins de difficultés pour modifier le site. De plus, certains CMS ont des limitations en termes de volume de pages, d’URL, Watermark …
- Ai-je connaissance des outils mis en place sur le site et l’entreprise ? ✅
Savoir et avoir les accès des solutions de gestion et de trackings simplifie l’audit car vous avez la possibilité d’analyser de nombreuses données que l’on ne peut avoir que via ces solutions.
Des solutions internes comme Google Analytics, la Google Search Console, Google Tag Manager ou externes comme Ahref, Hotjar, SemRush et bien d’autres.
- Ai-je connaissance du système de tracking du site à auditer ? ✅
Comment sont gérés le reporting et le tracking des performances et de l’activité ? Existent-ils ?
- Ai-je connaissance des objectifs du site et de l’audit ? ✅
Quels sont les objectifs du site en termes de KPI ? Plus de visites, une meilleure qualité de trafic, un meilleur taux de conversion…
Mais aussi des questions plus basiques comme les actions attendues des visiteurs sur le site (acheter, prendre contact, se renseigner…)
- Ai-je un historique des actions déjà effectuées en SEO ? ✅
Pour mieux comprendre les problèmes que vous trouverez lors de votre analyse. Il est important de connaître les actions déjà mises en place ou en cours.
Comme un changement de nom de domaine, une migration, l’arrêt de certains projets…
- Ai-je connaissance d’éventuels problèmes passés en lien avec le site ? ✅
Y a-t-il eu des problèmes avec les serveurs, le CMS, des erreurs humaines sur le site, des suppressions massives involontaires…
- Ai-je le nom des principaux concurrents du site ? ✅
Ici on va parler des concurrents directs mais aussi la concurrence sur Google. Avec par exemple des blogs ou sites spécialisés dans le secteur d’activité de l’entreprise et qui ne sont pourtant pas concurrents commercialement parlant.
3 – Le site face à Google
💡 Dans cette partie : Apprendre à connaître les premiers éléments à analyser et noter via Google pour votre audit technique SEO
Pourquoi Google ?
Je n’avais pas détaillé ce point en introduction mais la majorité des audits sont réalisés avec une analyse des critères de Google et uniquement Google. Pourquoi ?
Car Google possède quasiment toutes les parts de marché en France et à l’international pour ce qui est du marché des moteurs de recherche. En effet, Google a plus de 90% des parts de marché et cela tous appareils confondus. Le deuxième, Bing possède à peine 3%.
Face à cette situation de monopole, il est préférable de concentrer ses efforts sur le leader. De plus de très nombreux critères d’indexation et ranking sont les mêmes pour Google, Bing, Yahoo…
La première étape de cet audit technique est sûrement la plus simple et ne demande qu’une connexion internet et l’URL du site à auditer.
L’observation en plusieurs points de comment Google affiche le site audité va permettre de vous faire un premier avis et de comprendre un peu mieux le fonctionnement du site face aux crawlers de Google. En somme avoir une vision globale avant de rentrer dans les détails.
Faire une recherche Google simple et observer les résultats (web, image, vidéo …)
Allez sur Google et taper le nom de l’entreprise ou le nom qui fait le plus référence au site internet. Une fois cela fait vous devez vérifier :
- Si le site est en première position ;
- Si le site a des liens sitelinks ;
- Si la fiche Google My Business est présente (Google Business Profile) ;
- Si dans l’onglet “Images” votre logo et vos images sont bien présents ;
- Si dans l’onglet “Vidéo” votre vidéo de présentation est présente ;
- Si les suggestions suite au nom du site ou de l’entreprise sont cohérentes.
Si le site audité possède ces contenus mais ne répond pas favorablement à ces vérifications. Cela signifie que le site a vraisemblablement des erreurs et des optimisations sont à mettre en place.
Faire une recherche avec les opérateurs Google
Lorsque vous faites une recherche sur Google, vous tapez une phase ou une suite de mots pour espérer trouver le résultat le plus pertinent possible. Les opérateurs Google vont vous permettre d’affiner votre recherche et d’avoir un résultat de recherche très précis.
Voici un exemple avec l’opérateur site:
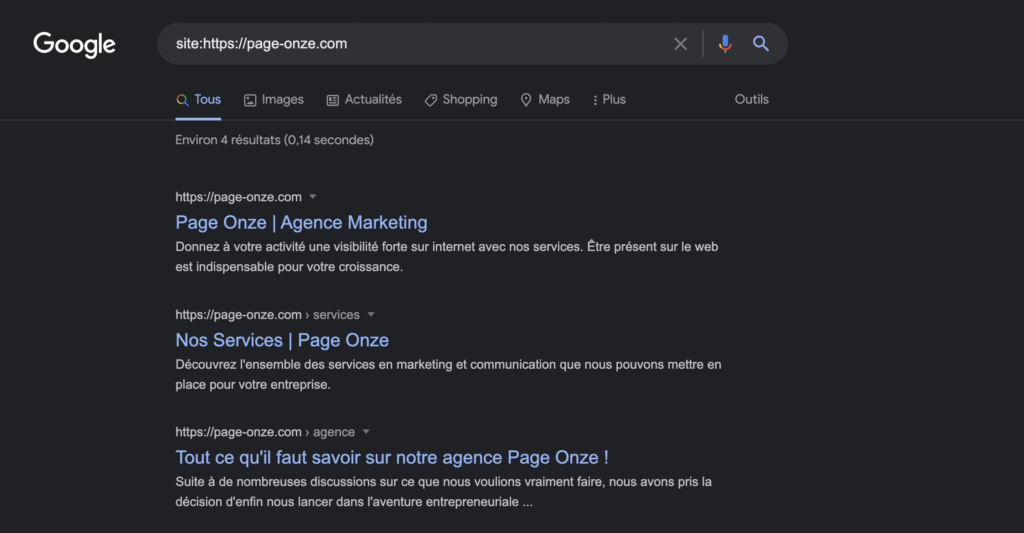
La commande site: permet de lister les pages du site audité qui sont présentes dans Google et donc dans l’index de Google.
Parmi l’ensemble des opérateurs disponibles certains sont utiles pour un audit SEO. Voici ceux que vous devez tester pour réaliser un audit technique SEO d’un site :
Voir le nombre de pages indexées sur Google
Comme dans l’exemple juste au-dessus, nous allons rechercher et noter le nombre de pages indexées par Google provenant du site en audit. Pour cela, il faut taper cette requête dans la recherche Google :
site:lesiteinternet.com
Le nombre de pages indexées se retrouve ici :
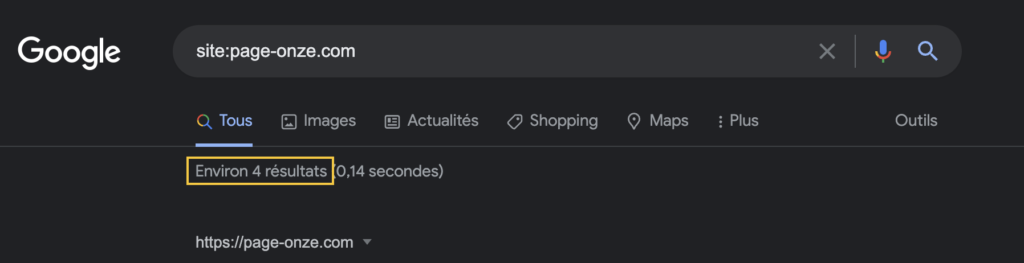
Cette donnée nous permettra (un peu plus tard dans cet audit) de faire une comparaison avec le nombre de pages du site pour savoir s’il y a des problèmes d’indexation Google (des pages sur votre site mais pas sur Google).
Voir la dernière version de la page stockée par le moteur de recherche Google
L’opérateur Google cache: permet de voir la dernière version de la page stockée par le moteur de recherche Google.
cache:lesiteinternet.com
Vous pouvez faire le test avec la page d’accueil du site et mettre en comparaison le résultat de la page requête et celui du site en live. Si les deux versions du site sont identiques = pas de problème
Suite à cet audit et aux optimisations que vous aurez réalisées vous pourrez vérifier que vos changements ont été pris en compte par Google avec cet opérateur.
À noter que si vous avez fait des changements sur le site dans les heures ou jours avant l’audit cela est parfaitement logique d’avoir l’ancienne version du site. Les Crawler Google ne passent pas sur votre site toutes les deux minutes.
Voir les documents PDF du site en ligne
Ici, nous allons utiliser deux opérateurs pour créer une seule requête qui va nous permettre d’afficher l’ensemble des fichiers PDF hébergés sur le site et indexés sur Google.
site:lesitesinternet.com filetype:pdf
Cela va vous permettre d’accéder à tous les fichiers PDF. Le but ici est plus de faire une inspection visuelle des résultats. Si en regardant les résultats vous constatez des PDF qui ne devraient pas être accessibles ou en ligne, vous devez récupérer toutes les URL présentes.
Dans la suite de cet audit, nous verrons comment bloquer l’indexation d’une page et donc d’un document.
Voir s’il y a des textes non souhaités en ligne
Ici, nous allons vérifier si sur le site il n’y a pas des contenus textes non voulus. L’exemple le plus simple est le “lorem ipsum”
site:lessitesinternet.com “lorem ipsum”
Lors de la création d’une page, souvent, pour éviter d’avoir des contenus textes vides, on ajoute ce que l’on appelle du lorem ipsum. Cela permet de rapidement se rendre compte à quoi va ressembler la page quand on aura rédigé un texte
Une bonne idée pour la création d’une page, toutefois il arrive souvent qu’il reste du texte comme celui-ci sur les pages car on peut oublier de retirer ces textes inutiles.
Cette requête va alors afficher toutes les pages qui contiennent au moins le texte “lorem ipsum” sur la page, les meta et plus largement les balises textes.
Vous pouvez modifier la requête en changeant les mots entre guillemets par d’autres textes que vous ne souhaitez pas voir sur le site en audit mais qui pourraient malheureusement être présent suite à un oubli.
4 – Les performances du site internet
💡 Dans cette partie : Apprendre à utiliser des outils externes pour analyser les performances d’un site internet
C’est un peu un audit dans un audit. Le but va être d’utiliser des plateformes externes pour réaliser un audit technique SEO.
Nous allons utiliser deux sites qui permettent de faire cela. Deux pour diversifier les sources et obtenir une meilleure analyse.
Ces outils s’intéressent principalement à la performance des pages et du site. Ici le terme performance regroupe principalement la vitesse de chargement des pages et du site.
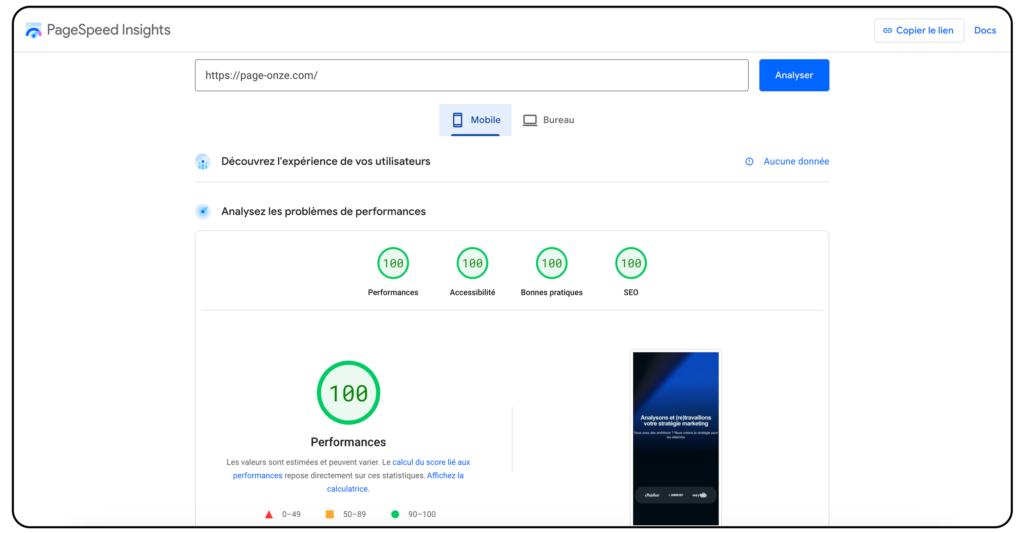
PageSpeed Insights
https://pagespeed.web.dev/
PageSpeed Insights est très simple à utiliser. Il suffit d’aller sur le site et de renseigner l’URL de la page dont vous souhaitez analyser les performances.
Dès lors que l’analyse sera terminée, vous aurez deux notes. L’une pour la version mobile du site et l’autre pour la version bureau. Votre note sera dans le vert si vous obtenez un score supérieur à 90.
Si toutefois vous avez une note proche de 90 mais en dessous, vous pouvez considérer qu’il s’agit également d’un très bon score. D’autant plus si la page que vous avez analysée contient de nombreux éléments (image, animation, vidéo…).
L’important avec cet outil sera de noter de côté les principaux éléments bloquants analysés par PageSpeed Insights et de continuer la suite de cette documentation.
Attention PageSpeed Insights analyse la page que vous avez saisie et non pas l’ensemble du site. Même si de nombreux critères et éléments sont les mêmes sur toutes les pages du site, il faut bien prendre en compte cette différenciation.
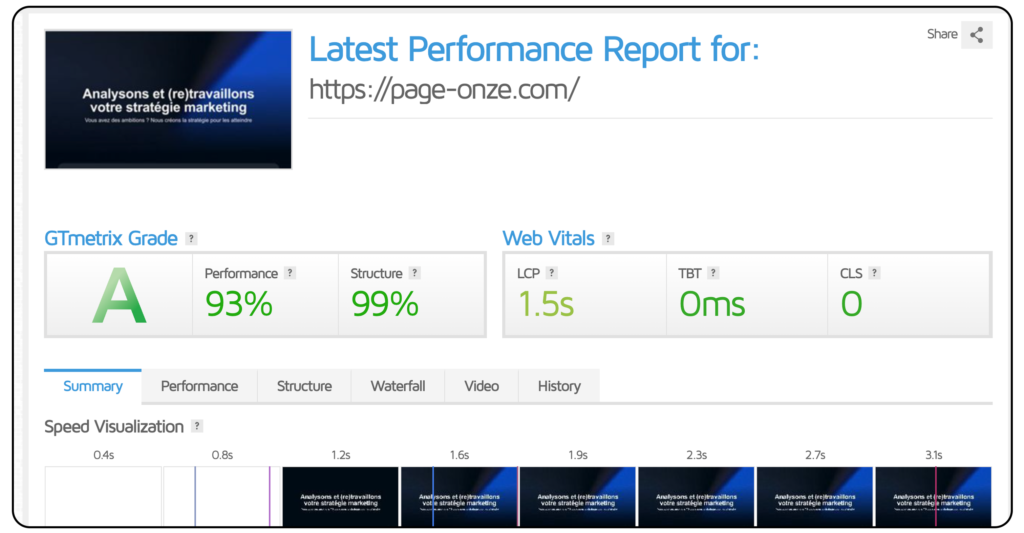
GTMetrix
L’outil GTMetrix s’intéresse lui aussi aux performances et plus particulièrement à la vitesse des sites internet. Son utilisation est également très simple, il suffit de renseigner une URL et de lancer l’analyse.
Le résultat vous donne une note entre A et F. A étant la meilleure et F la plus mauvaise.
Là aussi avec GTMetrix notez de côté votre note et les plus grosses difficultés que l’outil a découvert pour la suite de cet audit. Vous pourrez refaire une analyse après vos optimisations et voir l’évolution de votre note.
À noter que depuis peu vous devrez vous créer un compte gratuit pour l’utiliser.
5 – L’importance du HTTPS
💡Dans cette partie : Comprendre l’importance du HTTPS et vérifier que tout le site est bien sous ce protocole sécurisé
Nous allons vérifier si le site est bien en HTTPS. Puis qu’il ne reste pas des pages en HTTP dans l’index de Google.
Pour Google une page en HTTP et en HTTPS sont deux pages différentes même si le contenu est identique.
Pourquoi faut-il que les pages web soient en HTTPS ?
HTTP et HTTPS sont des protocoles de communication entre un client et un serveur par exemple entre un navigateur et un serveur.
Ainsi HTTP est une version non cryptée des échanges. Il est alors bien plus simple pour une personne tierce d’intercepter et de retranscrire les informations échangées en HTTP qu’en HTTPS. Le S prévalent pour Secure.
Depuis 2015, Google a déclaré qu’un site et donc les pages en HTTPS seront favorisées pour le référencement naturel. Le HTTPS est un critère pour le SEO.
Depuis déjà plusieurs années, les navigateurs vous précisent visuellement quand un site est en HTTP et en HTTPS comme sur Google Chrome :

Pour résumer, passer en full HTTPS permet de :
- Rassurer les visiteurs du site (affichage en vert et du cadenas) ;
- D’optimiser le référencement naturel ;
- Sécuriser et crypter les échanges entre le visiteur et le site ;
- Éviter d’avoir deux versions d’un site avec des pages en HTTP en HTTPS ;
Comment auditer les pages HTTP et HTTPS en trois étapes ?
1 – Vérifier le protocole HTTPS
La première chose à faire est de se rendre sur le site et de vérifier qu’une redirection vers HTTPS se fait quand vous ouvrez une page du site.
Si le site n’est pas en HTTPS, je vous invite à rechercher dans votre moteur de recherche le nom de votre hébergeur et HTTPS ou Certificat SSL (ex : “OVH HTTPS”) et de consulter la documentation de votre hébergeur.
On retiendra généralement 4 étapes :
- Obtenir un certificat SSL ;
- Mettre en place le certificat SSL sur votre serveur (hébergeur) ;
- Effectuer toutes les redirections 301 des pages en HTTP vers celles en HTTPS (voir Chapitre 5 pour mettre en place des redirections) ;
- Mettre à jour votre robots.txt, sitemap.xml et Google Search Console (voir Chapitre 6).
2 – Vérifier toutes les pages en HTTP du site
Nous allons utiliser un outil gratuit disponible sur PC et Mac, Screaming Frog. Je vous invite à le télécharger puis l’installer. Cet outil va permettre de crawler les pages du site pour observer les pages en HTTP et le statut des pages pour savoir si elles ont été redirigées ou non.
Il suffit de saisir l’URL du site indexé et d’observer les résultats. Vous pourrez aller dans l’onglet “Protocol” pour observer s’il y a des pages en HTTP et si elles sont redirigées. Status Code (301 pour les rediriger et 200 pour les ok) et Status (Moved Permanently)
Vous pouvez faire un export de la liste pour la mettre dans un Google Sheets pour suivre plus facilement les pages HTTP qu’ils restent à rediriger.
https://www.screamingfrog.co.uk/seo-spider/
3 – Vérifier les pages HTTP indexées
Cette étape n’est pas obligatoire si vous avez réalisé à 100% l’étape 2. Toutefois, elle vous sera utile pour voir si Google a bien vu et suivi les changements et redirections que vous avez effectués.
Ici, comme dans le Chapitre 2, nous allons utiliser les opérateurs dans les recherches Google.
Nous allons vérifier toutes les pages du site audité qui sont indexées en HTTP sur Google. Pour cela nous allons utiliser l’opérateur site:inurl: et le signe – pour exclure un élément dans la recherche.
Nous obtenons cette requête à saisir :
site:lessitesinternet.com -inurl:https
Cette requête va afficher toutes les pages du site indexées moins celle qui ont un https dans l’url. Ainsi, si vous avez des résultats, il s’agira de toutes les pages en HTTP que Google a indexées. Si vous avez fait l’étape 2 à 100% vous avez déjà la liste de l’ensemble des pages que vous devrez rediriger.
Dès lors que vous avez effectué toutes les redirections, il faudra un peu de temps pour Google pour mettre à jour son index avec les nouvelles pages en HTTPS.
Vous pouvez vous noter cette requête pour dans quelques mois puis vérifier que toutes les redirections ont bien été prises en compte par Google.
6 – Détection et résolution des pages en erreurs
💡 Dans cette partie : Connaître l’ensemble des codes erreurs que l’on peut trouver sur des pages d’un site et comment les résoudre
Comme nous venons de le voir HTTP est un protocole qui fonctionnent sur le principe de la communication entre un client et un serveur. Le plus souvent il n’y a pas de problème toutefois en cas d’erreur on retrouve un ensemble de codes.
Les pages en erreurs d’un site peuvent être nombreuses et difficiles à détecter. Dès lors qu’il y a un problème de communication entre le client et le serveur cela envoi un mauvais signal à Google lors du crawl des pages et bloque les visiteurs pour naviguer sur le site.
Le protocol HTTP permet de nous donner des codes qui vont correspondre à un statut de la page. En analysant ces codes, nous pouvons trouver les pages en erreurs et les résoudre.
L’exemple le plus courant est une page supprimée sur votre site mais qui est encore accessible depuis Google. Pour éviter cela, nous allons détecter les pages en erreurs pour les corriger.
Voici un schéma qui résume la communication via le protocole HTTP entre un utilisateur et un serveur web. Il permet de mieux comprendre quand et comment fonctionnent les réponses HTTP et les codes de statut que l’on peut recevoir à l’affichage sur nos postes.
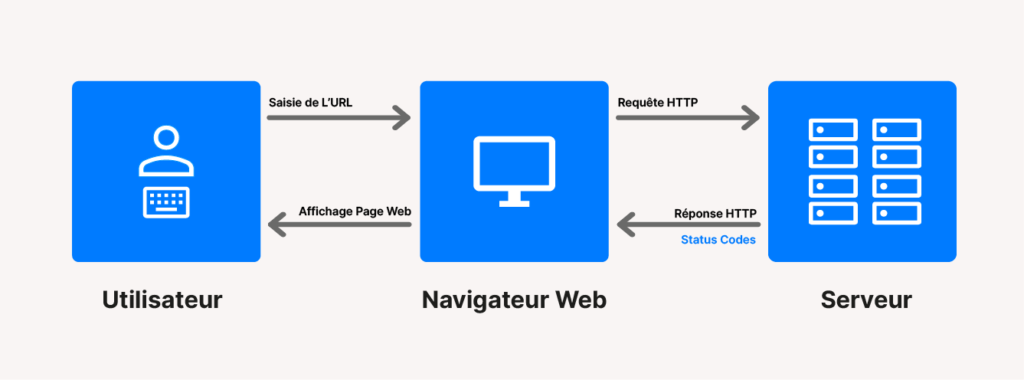
Quels sont les codes HTTP que l’on rencontre le plus souvent lors d’un audit de site
Code 200 :
Cela signifie que la requête que vous avez demandée, c’est-à-dire accéder à la page, a bien fonctionnée. Il n’y a pas de pages en erreur et la page a bien été chargée.
Code 301 & 302 :
Ces codes correspondent à des redirections. Une redirection signifie que la page que vous souhaitez consulter n’est plus disponible à l’URL sélectionnée et que vous allez être redirigée vers une autre page. Le code 301 correspond à une redirection permanente et le code 302 a une redirection temporaire.
Dans la plus grande majorité des cas, cela provient d’une action volontaire.
Par exemple si vous supprimez une page de votre site, les personnes ne pourront plus accéder à cette page avec un code 200. On met alors en place une redirection pour rediriger les visiteurs vers une autre page.
Code 401 & 403 :
Ces deux codes d’erreurs signifient que la requête a bien été comprise mais que son accès vous est interdit. Vous ne pouvez pas accéder à cette page. Cela est le cas par exemple sur les sites où vous devez vous identifier pour accéder à des pages ou du contenu.
Code 404 :
Ce code correspond à une page que le serveur n’arrive pas ou plus à trouver. Cela est souvent le code erreur que l’on a quand une page d’un site a été supprimée sans faire de redirection ou quand vous faites une faute de saisie dans l’URL de la page. (Erreur 404).
Code 5XX :
Les erreurs commençant par 5 sont des erreurs liées au serveur. Les codes 500, 503 et 504 étant les plus courants signifiants que le serveur n’est pas accessible et donc que le contenu de la page présent sur le serveur n’est pas accessible. Il s’agit souvent d’un problème avec l’hébergement du site.
Comment trouver les codes HTTP des pages et les analyser ?
Pour analyser efficacement toutes les pages nous allons utiliser l’outil Screaming Frog SEO Spider. L’outil est gratuit jusqu’à l’analyse de 500 pages. Ce qui est souvent suffisant.
Si cela n’est pas suffisant vous pouvez soit passer à la version payante soit découper les URL du site par sous répertoire pour avoir l’analyse de chaque répertoire puis de tous les regrouper pour avoir l’analyse complète. (https://www/monsiet/blog/…)
Ici, nous allons saisir l’URL du site dans Screaming Frog. Dans ce chapitre, nous allons principalement nous intéresser à la colonne Code HTTP et Statut.
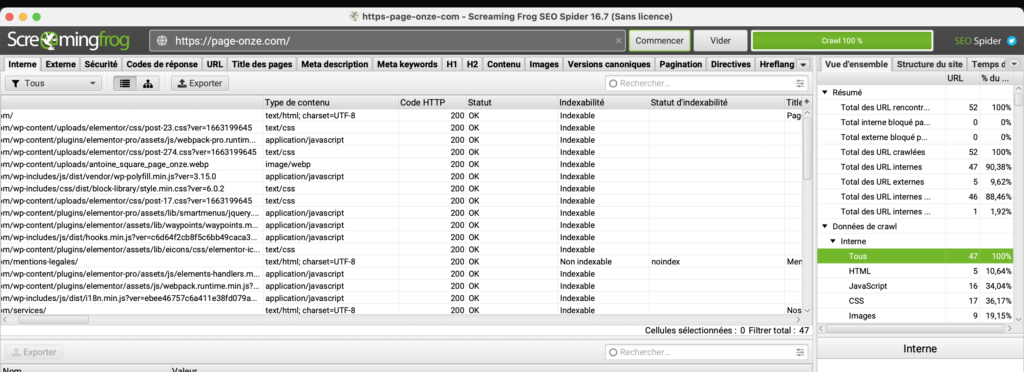
1 – Si la page affiche un code Status 200, c’est parfait la page est accessible et ne présente pas d’erreur pour y accéder.
2 – Si la page affiche un code Status 301 ou 302. Il y a bien une page qui est accessible par le visiteur mais il ne s’agit pas de la page indiquée par l’URL.
Une redirection a été mise en place. Vous devez analyser si la redirection effectuée correspond bien à ce que vous voulez. Si cela ne redirige pas vers la bonne page, pensez à changer cette redirection par la bonne URL.
3 – Si la page affiche un code Status 404. La page n’est pas accessible et aucune redirection n’a été mise en place. Il en résulte une page en erreur 404 avec aucun contenu. Il faut alors rediriger cette URL vers une URL en code status 200 pour résoudre cette erreur.
Comment effectuer une redirection d’une ou plusieurs pages ?
Pour effectuer des redirections de pages vous devez soit avoir accès au CMS soit accès au dossier racine du site.
Si le site audité est basé sur une technologie WordPress, le plus simple est d’ajouter une extension qui vous permet de faire des redirections. L’extension la plus simple à utiliser possiblement “Redirection par John Godley”
Il suffit de renseigner l’URL en erreur puis dans un deuxième temps celle ou les visiteurs doivent être redirigés.
Une autre possibilité pour effectuer des redirections de pages est de la faire directement depuis le fichier htaccess.
Un fichier .htaccess se trouve dans le dossier racine de votre hébergement d’un site. Vous pouvez y accéder via un accès FTP avec par exemple FileZilla. Dès lors que vous aurez accès à ce fichier vous pourrez y ajouter des nouvelles lignes pour effectuer des redirections des pages.
On appelle un dossier racine, l’emplacement le plus haut hiérachiquement, le dossier premier qui va contenir tous les autres dossiers.
Voici un exemple de ce que vous devez ajouter dans le fichier .htaccess pour effectuer une redirection permanente d’un lien vers un autre.
RewriteRule ^page-en-erreur.html$ https://www.votresite.com/nouvelle- page.html [R=301,L] Redirect permanent /ancienne_page.html https://nouvelle-page.xyz
Dès que vous avez modifié puis enregistré votre redirection, vous pouvez tester en vous rendant sur l’ancienne URL pour voir si vous êtes bien redirigé vers la nouvelle page.
C’est aussi via le fichier .htaccess que vous pouvez effectuer toutes les redirections des pages en HTTP vers les pages en HTTPS.
Les pages orphelines
Ce que l’on nomme des pages orphelines sont des pages qui n’ont aucun lien avec d’autres pages du site.
L’existence de ce type de pages est problématique si ces pages sont indexées et consultées par des visiteurs.
Car ces pages ont bien souvent peu d’intérêt ou du contenu obsolètes qui peuvent nuire à votre stratégie SEO à cause de pages non souhaitées. Elles ne vont pas contribuer à l’augmentation de la notoriété du site.
Deux solutions pour détecter les pages orphelines d’un site :
Via Screaming Frog
Screaming Frog vous permet aussi de détecter d’éventuelles pages orphelines. Pour cela après avoir effectué une recherche. Il faut aller dans l’onglet “Reports” puis en cliquant sur “Orphan Page”
Cela va vous créer un fichier CSV que vous pourrez ouvrir dans un tableur (Excel, Google Sheets …)
Via la comparaison de fichiers
Dans un premier temps nous allons générer un fichier Sitemap XML qui va inclure toutes les URL présentes dans la base de données pour obtenir la liste des pages du site.
La deuxième étape va être d’utiliser un crawler pour aussi lister toutes les pages du site qui sont elles accessibles par Googlebot.
Dès lors que nous avons nos deux listes, nous pouvons faire une comparaison pour voir les écarts. Les pages orphelines seront les pages présentes dans le fichier Sitemap mais pas dans celle du crawler.
Attention, cette deuxième méthode est moins fiable car certaines pages n’ont peut être pas encore été indéxées par Google. Je vous recommande d’utiliser, la première méthode avec Screaming Frog.
Outil alternatif à Screaming Frog : https://www.deadlinkchecker.com/
7 – Google : indexation & exploration des pages
💡 Dans cette partie : Savoir si le site donne les bonnes informations aux robots Google pour qu’ils puissent indexer les pages du site.
Si le site audité est récent et/ou ne publie pas régulièrement du contenu, les robots de Google ne passeront pas régulièrement et n’indexeront pas les nouvelles pages qui seront publiées. Mais des solutions existent pour pousser l’indexation.
Ce chapitre sera aussi l’occasion de voir comment ne pas indexer ou demander à désindexer des pages du site.
Commençons par connaître le nombre de pages présentes dans l’index de Google
Comme vu dans le Chapitre 2, nous allons utiliser l’opérateur site: pour connaître toutes les pages indexées du site audité.
Ici vous pouvez regarder le nombre de résultats affichés en dessous du résultat de la requête. Si le site audité comprend des centaines de pages, il faudra scraper l’ensemble des résultats pour avoir une meilleure visualisation des pages (dès lors que vous n’avez pas la Google Search Console)
Toutes les pages du site qui ne seront pas comprises sur cette requête Google sont alors des pages que l’on ne pourra pas retrouver via une recherche Google.
Pour comprendre tout cela, nous allons voir les différentes façons de déclarer à Google les pages que l’on souhaite qu’il explorent et/ou indexent.
Le fichier robots.txt
Un fichier robots.txt permet de donner des indications à l’ensemble des robots d’exploration sur les pages qu’ils doivent regarder ou non sur un site. Ainsi avant de commencer à explorer les URL de votre site, les robots iront consulter le robots.txt en premier.
Il va essentiellement servir à interdire aux robots d’explorer certaines pages ou parties d’un site. Attention, interdire d’explorer ne signifie pas nécessairement ne pas indexer. Vous pourrez trouver des URL indexées mais sans titre et sans description car le robot Google n’aura pas lu la page (un cas rare mais possible).
Ce fichier texte est situé à la racine de votre site web, c’est-à-dire dans le répertoire de base celui dont on ne peut pas remonter plus haut.
Voci un exemple d’un fichier à la racine d’un site :
• https://www.google.com/robots.txt
Un fichier qui n’est pas à la racine d’un site :
• https://www.google.com/fr/blog/robots.txt
Quelques règles pour lire un fichier robots.txt :
• User-agent: * signifie que la suite des informations s’adresse à l’ensemble des robots. Vous pouvez personnaliser les indexations en saisissant le nom du ou des robots à la place de * (exemple : User-agent: Googlebot)
• Disallow: / (cela va indiquer que tout est interdit)
• Disallow: (cela va indiquer que tout est autorisé)
• Allow: / (Vous pouvez utiliser le Allow mais attention à l’ensemble des autres règles pour ne pas créer des conflits)
• # (cela permet de mettre un commentaire dans votre fichier)
• Sitemap : “lien du fichier sitemap” (va indiquer le sitemap de votre site, sitemap que nous verrons juste après)
Pour ne pas indexer une page, on préférera utiliser une balise noindex que nous verrons un peu plus loin dans ce Chapitre.
Le site possède-t-il un fichier robots.txt ?
Deux solutions rapides :
Par convention et pour les crawlers, les fichiers robots.txt sont placés à la racine des sites internet. On va alors récupérer l’URL du site et ajouter /robots.txt. Si vous avez un résultat, il y a un fichier robots.txt et si vous avez une erreur 404 vous pouvez être quasiment sûr qu’il n’y a pas de robots.txt.
Utiliser une solution tierce pour rechercher un robots.txt : https://fr.ryte.com/free-tools/robots-txt/
Comment créer ou modifier un fichier robots.txt ?
Pour créer un fichier, il suffit d’ouvrir un éditeur de texte ou un simple bloc-notes et de saisir les instructions que vous souhaitez mettre en place pour le site. Il existe déjà des fichiers tout fait sur internet à copier/coller.
Vous devrez ensuite l’enregistrer au format texte (.txt) et le nommer robots.txt Une fois cela fait, vous devrez le placer à la racine de votre site.
Le plus simple est d’accéder au serveur de votre site via un outil comme Filezilla et d’uploader le fichier robots.txt. Pour le modifier, il suffira de compléter le fichier et de bien le sauvegarder.
À savoir que si vous êtes sous WordPress et que vous possédez l’extension Yoast vous pourrez créer et modifier votre fichier robots.txt depuis Yoast.
Voici l’exemple le plus basique d’un fichier robots.txt qui va permettre à tous les robots d’explorer toutes les pages. Et dans un deuxième temps une ligne pour indiquer l’emplacement de votre fichier Sitemap.
User-agent: * Allow: / Sitemap: https://www.example.com/sitemap.xml
Voici deux ressources pour en savoir plus sur la gestion des fichiers robots.txt
• http://www.robotstxt.org/robotstxt.html
Qu’est-ce qu’un fichier sitemap.xml ?
Un fichier sitemap.xml est un fichier destiné aux robots d’indexation et donc aux moteurs de recherche. Ce fichier va principalement lister l’ensemble des pages que vous souhaitez voir indexer dans les moteurs de recherche.
Il va ainsi simplifier le travail de recherche des robots et donne la possibilité d’indexer plus rapidement les pages d’un site.
Ce fichier est situé à la racine de votre site web et il est fortement conseillé de l’ajouter dans votre robots.txt ainsi que de le déclarer dans la Google Search Console.
Mettre en place et déclarer ce type de fichier est important si vous avez un site avec de nombreuses pages, si votre site est très récent ou encore si vous vous apercevez que certaines pages du site ne sont pas indexées.
Le site possède-t-il un fichier sitemap.xml ?
Il existe plusieurs solutions pour trouver un fichier sitemap.xml. Si jamais vous ne trouvez pas le fichier, il est fortement probable qu’il n’y a pas de sitemap.xml ou qu’il soit très mal utilisé.
Rechercher à la main :
Par convention et pour les crawlers les fichiers sitemap.xml sont placés à la racine des sites internet. On va alors récupérer l’URL du site et ajouter /sitemap. xml (www.example.com/sitemap.xml)
Rechercher sur le serveur :
Le fichier n’a pas obligatoirement le nom exact de sitemap.xml. Si vous avez accès au serveur, vous pouvez aller voir dans les fichiers du serveur via Filezilla et voir s’il y a un fichier en .xml ou bien contenant le mot sitemap dans le nom du fichier.
Regarder dans le robots.txt :
Il est conseillé d’ajouter le fichier sitemap dans le fichier robots.txt pour faciliter le travail des robots d’indexation. Vous pouvez possiblement trouver le lien du fichier sitemap dans le robots.txt du site
Rechercher dans la Google Search Console :
Si le site est déjà en ligne depuis un moment, il se peut qu’une personne ait déjà indiqué l’emplacement du site sur la Google Search Console. Pour cela il faut aller sur la Google Search Console et cliquer sur Sitemap.
Si vous n’avez rien trouvé, vous pouvez partir sur le fait que le sitemap.xml n’est pas présent et penser à en créer un.
Comment créer et modifier un fichier sitemap.xml ?
Pour créer un fichier sitemap.xml :
Pour créer un fichier sitemap basique, vous pouvez utiliser la solution Screaming Frog. Il vous suffit de crawler le site dont vous souhaitez générer un fichier sitemap.xml. Puis de cliquer sur Sitemaps puis sur XLM Sitemap. Vous aurez alors une box avec plusieurs options disponibles, le principal est de garder les pages en HTTP 200.
Dès lors que vous avez validé vos choix, un fichier sera généré automatiquement et vous pourrez l’enregistrer ou vous le souhaitez sur votre ordinateur.
Vous pouvez ensuite ajouter ce fichier à la racine de votre serveur.
Le défaut de cette solution est qu’il est généré à un instant T. Si vous créez de nouvelles pages, elles ne seront pas ajoutées dans ce fichier sitemap.xml
À savoir que si le site est sous WordPress, il existe des extensions pour générer et ajouter automatiquement toutes les pages du site. Yoast SEO vous permet de faire cela par exemple.
Pour modifier un fichier sitemap.xml :
Vous pouvez modifier ce fichier avec tous les éditeurs de texte. Vous pourrez par exemple retirer des pages du sitemap ou ajouter les nouvelles que vous avez créées. N’oubliez pas de sauvegarder et d’importer votre fichier dès lors que vous l’avez modifié.
Petite astuce, vous pouvez aussi indiquer les Flux RSS comme sitemap.xml
Le mieux reste d’utiliser une solution qui vous permet de générer et mettre à jour automatiquement votre Sitemap. Aujourd’hui presque tous les CMS laissent la possibilité de créer ce fichier et de le mettre à jour.
Si vous avez trouvé un fichier sitemap.xml, il est toujours intéressant de le lire pour mieux connaître la structure du site.
Cela peut vous permettre de découvrir des pages du site qui ne sont pas nécessairement simples à trouver à cause de la navigation du site. Mais cela permet également de détecter des problèmes d’indexation ou de référencement s’il y a des omissions ou des erreurs dans sa génération.
Mettre en place une stratégie de lien
Une autre solution pour améliorer l’indexation et l’explorabilité du site audité est d’analyser et de mettre en place une stratégie de lien. Aussi bien avec la gestion des liens internes que la gestion des liens externes du site.
Nous reviendrons sur ces deux notions de liens dans quelques chapitres.
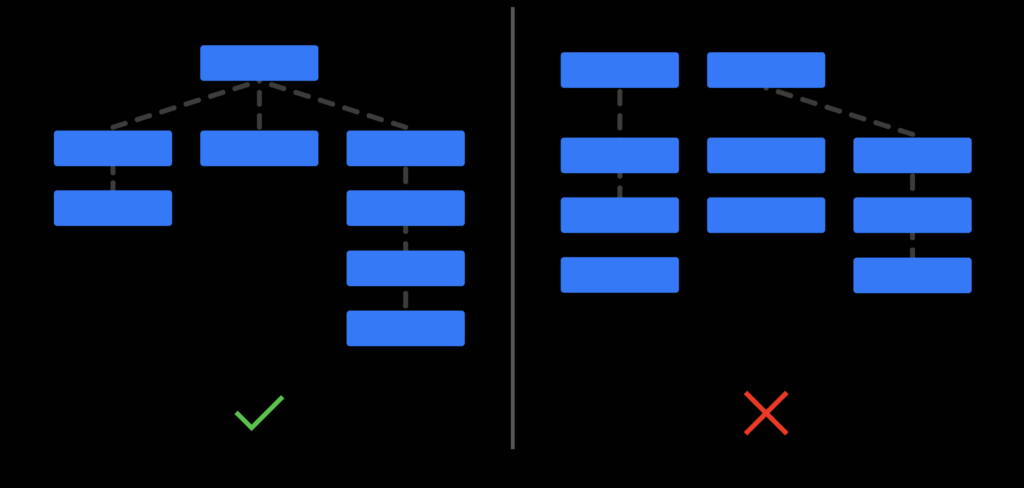
Il faut garder à l’esprit qu’un site internet et l’ensemble de ses pages doivent être organisés et hiérarchisés. Cela permet de simplifier l’expérience utilisateur des visiteurs mais aussi de simplifier le travail de découverte et de compréhension de votre site par les robots d’indexation.
On va alors vérifier qu’il n’y a pas de pages orphelines comme vu précédemment et que la hiérarchisation des pages se fait bien dans les deux sens ascendant et descendant.
Les balises index et noindex
Lors d’un audit, vous allez avant tout chercher les points qui peuvent être améliorés et optimisés sur le site.
Et à travers l’indexation des pages, on va parfois vouloir ne pas mettre en ligne ou ne pas indexer une ou plusieurs pages dans les moteurs de recherche.
Comme vu dans la partie sur le robots.txt, on peut déclarer aux robots de ne pas accéder à une ou plusieurs pages mais cela ne pas va garantir la non-indexation des pages à 100%.
Pour ne pas indexer une page, il faut utiliser une balise Meta à destination des robots d’exploration “Meta Name Robots”. Exemple avec la balise “index”.
<meta name='robots' content='index, follow,max-image-preview:large, max-snippet:-1, max-video-preview:-1' />
Cette balise est aussi pratique si vous ne pouvez pas accéder ou créer un robots.txt
Pour que l’ensemble des robots d’exploration n’indexent pas une page du site audité vous devez ajouter cette balise Meta dans le <head> de la page
<metaname='robots' content='noindex'>
Pour ne plus que la page soit en ligne (si elle l’était précédemment). Vous devrez attendre que les robots repassent sur votre site pour qu’elle soit ensuite deindexée. Le fait de mettre la balise ne va pas retirer la page des moteurs de recherche instantanément.
À l’inverse vous pouvez mettre une balise Meta pour indexer une page avec cette balise (souvent fait par défaut avec les CMS) :
<meta name="robots" content="index">
Attention toutefois si vous avez fait le choix d’inscrire dans le fichier robots.txt des pages ou répertoires à ne pas explorer. Il y a de forte chance que les pages ne soient pas lues par les robots et donc ils ne pourront pas lire les balises Meta Robots sur les pages.
C’est assez logique quand on y pense mais cela peut être problématique surtout si vous passez des pages de noindex en index mais qui sont encore bloquées dans le robots.txt
La balise canonical
La balise canonical est pratique pour éviter du contenu dupliqué aux yeux de Google.
Elle permet de déclarer d’où vient le contenu original et permet de déclarer une autre page comme une copie du contenu original. Cela va permettre aux robots de comprendre qu’il s’agit d’une copie et d’une copie souhaitée de la page.
Vous pouvez ainsi mieux maîtriser la gestion du contenu du site audité et donner les bonnes informations à l’ensemble des robots d’indexation.
Voici un exemple d’une balise canonical que vous pouvez ajouter dans le <head> d’une page.
<link rel="canonical" href="https://antoine-moulard.com/" />
Il faut ajouter l’URL source de la page ou de l’article original.
La Google Search Console
La Google Search Console est un outil développé par Google qui permet d’avoir plus d’informations sur un site internet mais aussi de donner plus d’informations aux robots Google.
Sur la partie gauche de la Search Console vous avez 3 modules :
• Pages
• Sitemaps
• Suppressions
Pages :
L’espace Pages vous permet de connaître l’ensemble des pages du site qui ont été indexées et toutes celles qui ne sont pas encore indexées ou excluses. Cela permet de mieux comprendre l’indexation du site audité mais aussi de comprendre les raisons d’exclusions.
Sitemaps :
Vous pouvez ici ajouter le lien du sitemap d’un site internet pour que Google puisse le trouver plus facilement. Cela permet également de suivre l’état d’indexation du ou des sitemaps que vous avez déclaré dans la Google Search Console et la date de la dernière exploration des robots.
Suppressions :
Cela vous permet de faire une demande pour supprimer du contenu qui apparaît dans les résultats de recherche. Vous pouvez soumettre une URL exacte ou bien un préfixe d’URL pour supprimer l’ensemble des liens d’un répertoire.
Il s’agit d’une demande, donc elle ne sera pas obligatoirement prise en compte et la suppression n’est que temporaire et non pas définitive.
En saisissant une URL dans la barre de recherche de la Google Search Console, vous aurez des informations sur la couverture de la page. Mais aussi la possibilité de faire une demande d’indexation de la page.
La Google Search Console est un outil très complet et riche en données.
8 – Navigation et architecture du site internet
💡 Dans cette partie : Comprendre l’importance de l’expérience utilisateur pour optimiser les pages, le contenu et les performances du site
Le header (entête du site) est important car il s’agit du principal emplacement pour trouver les informations que l’on recherche sur un site. De plus il est présent sur toutes les pages.
Commençons par analyser le header du site internet avec une petite liste de questions :
- Le Header est-il responsive ? (tablette et mobile)
- Les principales pages du site sont-elles dans le header ?
- Les textes des liens sont-ils pertinents avec les pages qu’ils retournent ?
- Cliquer sur le logo dans le header mène-t-il vers la page d’accueil du site ?
- Il y a t’il des problématiques de gestion de clics sur le header ou dans les sous-menus du header
- L’architecture de la profondeur des pages est-elle respectée dans le header ?
- N’y a t-il que les pages essentiels dans le header ? (si trop de liens penser à en retirer ou reclasser)
- Le choix de la langue du site est-il disponible dans le header ?
- Un panier pour les sites e-commerce ?
- Un call to action dans le header ? (réservez, appelez, demandez de devis)
Le footer ou pied de page :
- Il y a t’il les principales pages du site ?
- Les réseaux sociaux sont-ils présents ?
Quelques autres petits conseils pour la navigation sur le site :
- Éviter d’avoir un curseur de souris personnalisé sur le vite ;
- Éviter d’avoir des éléments sonores qui se déclenchent automatiquement ;
- Le scroll doit se faire sans interruptions ;
- Éviter une vitesse de scroll personnalisée ;
- Est-ce que certaines pages sont trop profondes (au-délà de 3 clics à partir de la page d’accueil) ?
Toujours garder en tête de simplifier un maximum la navigation de votre site car tout le monde n’a pas la même expérience que vous sur internet. Il faut penser à ceux qui visitent et consultent peu de sites internet mais qui pourraient passer sur le site.
9 – Le balisage des pages du site (Hn, Meta)
💡 Dans cette partie : Connaître les principales balises HTML qui ont un impact sur le référencement et les performances d’un site internet
Le balisage d’un site est important pour son référencement sur les moteurs de recherche. Si l’on met de côté le contenu en lui-même d’une page. Il s’agit de la base pour le référencement mais aussi techniquement pour avoir un site propre et bien ordonné.
Les balises liées à une page
La balise Title
La balise Meta Name Title va correspondre au titre que vous voyez quand vous faites une recherche dans les moteurs de recherche.
C’est aussi le titre qui va s’afficher comme nom dans l’onglet de votre navigateur. Elle est très importante pour le référencement de votre site et doit être ajoutée et unique sur toutes les pages d’un site.
Pour un affichage non tronqué sur les moteurs de recherche, on évite qu’elle fasse plus de 65 caractères.
Voici un exemple du point de vue du code :
<title>Page Onze | Agence Marketing</title>
On peut également la retrouver sous ce format :
<title>Page Onze | Agence Marketing</title>
La balise Meta description
La balise Meta Name Description va correspondre à la description que l’on trouve sous les titres des recherches que l’on effectue sur les moteurs de recherche. Elle est aussi souvent utilisée dans les extraits courts quand vous partagez un lien.
Avec l’affichage des moteurs de recherche, on évite qu’elle fasse plus de 150 caractères.
Voici un exemple du point de vue du code :
<meta name="description" content="Donnez à votre activité une visibilité forte sur internet avec nos services. Être présent sur le web est indispensable pour votre croissance." />
La balise Meta Canonical
La balise Meta Canonical est une balise qui va signaler aux moteurs de recherche qu’une page propose du contenu dupliqué, qui est reprise d’une autre page. Cela permet d’éviter d’être vu comme du duplicate content (contenu dupliqué).
Voici un exemple du point de vue du code :
<link rel="canonical" href="https://" />
La balise Meta Name Robot
La balise Meta name Robots est une balise qui est destinée aux robots d’indexation des moteurs de recherche. Vous pouvez ainsi déclarer sur une page grâce à cette balise si vous souhaitez qu’une page soit indexée ou non sur les moteurs de recherche.
Voici un exemple du point de vue du code :
<meta name="robots" content="index, follow">
Il existe de nombreuses autres balises de type Meta
Avec notamment toutes les balises Open Graph pour avoir un meilleur affichage sur les réseaux sociaux par exemple.
<meta property="og:image">
Pour afficher une image lors des previews de lien
https://developers.google.com/search/docs/advanced/crawling/special-tags
Les balises liées au contenu d’une page
Il s’agit des balises qui vont être utilisées pour rédiger ou mettre en forme le contenu d’une page. Même si l’on peut penser qu’elles sont uniquement utiles pour l’aspect visuel d’un site, elles sont prises en compte pour le référencement d’un site internet.
La balise <p>
Il s’agit de la balise la plus classique pour ajouter votre texte sur une page. La grande majorité du texte sur une page est écrit à l’intérieur d’une balise p. Cette balise est utilisée pour des paragraphes de texte.
Il s’agit du contenu de base qui sera lu par Google et ses robots d’indexation Pour les titres d’une page ont passera par des balises de Heading.
La balise bold
La balise Bold <b> va vous permettre de mettre en gras un mot dans un titre et dans une paragraphe de texte.
Au-delà de l’aspect visuel de la mise en gras d’un mot. Cette balise va avoir son importance car elle va permettre d’indiquer aux robots d’indexation que ces mots en gras sont importants dans le texte.
Il est ainsi conseillé de mettre en gras et donc dans une balise Bold, les mots-clés de votre pages ou les variantes de vos mots-clés. Oui il y a un débat entre Strong ou Bold pour le SEO les deux fonctionnent.
Les balises pour le Heading
Si vous avez déjà touché un peu à un site internet, vous avez déjà vu des éléments comme “HEADING 1” ou des balises <h1> … </h1>.
Ces balises représentent des titres pour une page web. Elles permettent, d’une part de structurer proprement le contenu d’une page et d’une autre part de me mettre en valeur du texte pour les robots d’indexation de Google.
Ainsi le texte saisi à l’intérieur d’une balise H1 va être plus important aux yeux des robots d’indexation qu’une balise <p> classique. Il faut donc apporter un soin particulier à ses titres si vous souhaitez optimiser le référencement de votre site.
La balise H1 est souvent utilisée comme le titre d’une page. Il est conseillé d’en utiliser une seule par page. Il n’est pas interdit d’en ajouter plusieurs mais préférez en ajouter qu’une seule.
Il existe six niveaux de balise pour le Heading allant de H1 à H6. La balise H1 est plus importante que la H2. La balise H2 est plus importante que la balise H3 et ainsi de suite jusqu’à la balise H6.
À l’inverse de la H1, il est recommandé d’utiliser plusieurs balise H2, H3, H4 dans vos pages. Le but va être de les utiliser de la même façon qu’on structure un livre avec des titres de chapitres, des titres de sous-chapitres et titres de paragraphe…
À noter que les balises H5 et H6 ont très peu d’importance en SEO pour les robots d’indexation. À moins d’avoir une page avec beaucoup de texte à classer, vous préférerez utiliser une balise <p> pour le reste de votre contenu.
10 – Les contenus du site
💡 Dans cette partie: Comprendre l’ensemble des optimisations que l’on peut mettre en place sur le contenu d’une page et d’un site
Les images
Les images sur un site internet sont des éléments indispensables dont il faut prendre soin.
Malgré ce que l’on peut penser, deux images identiques visuellement peuvent être très différentes au niveau de l’optimisation.
L’optimisation des images est ainsi un point très important à étudier pour un Audit Technique SEO.
Regardons ensemble les critères à analyser et optimiser pour toutes les images d’un site internet. Des optimisations qui auront des impacts sur le temps de chargement de vos pages aussi que sur le référencement du site dans les résultats de recherche et sur Google Images.
Le nom des images
Le nom du fichier que vous importez sur votre site à une importance pour le référencement de l’image et du site. Il est conseillé d’être clair dans le nom d’une image en ajoutant les mots-clés de la page dans le nom de l’image.
Le poids des images
Il s’agit de l’élément le plus important à analyser pour une image lors d’un audit technique SEO.
L’idée est de garder la même qualité d’image sur un site tout en réduisant son poids. Car plus une image sera lourde plus elle sera longue à charger.
Cela va entraîner deux pénalités :
- Google n’appréciera pas votre site car il est lent et aura du mal à charger. Vos pages seront moins mises en avant car la vitesse de chargement fait partie des critères de références d’une page et d’un site pour Google.
- La deuxième pénalité va être du point de vue de l’utilisateur. Vous avez peut-être déjà fait l’expérience d’un site lent à charger avec des images qui ne s’affichent pas. C’est assez agaçant et on peut vite faire un retour en arrière pour consulter une page d’un autre site qui lui se chargera plus vite.
La solution la plus populaire est de passer par des sites qui sont spécialisés dans la réduction du poids des images. On retrouve par exemple :
Pour réduire le poids d’une image vous pouvez aussi changer la qualité de l’image lors de votre export si vous avez créé un visuel. (Un poids de plus 1Mo est à éviter pour une image)
La taille des images
Quand je parle de taille, il faut comprendre la dimension de votre image avant de l’importer sur un site internet. Ainsi, il n’est pas nécessaire d’avoir une taille d’image plus grande que l’espace qui lui ai dédié sur un site internet.
Par exemple, une photo de profil d’un testimonial n’a pas besoin de faire 800x800px. Une taille de 200x200px dans ce cas est largement suffisante.
Plus l’image sera grande plus son poids sera grand, autant réduire la taille de l’image à l’essentiel pour son affichage.
La solution pour changer la taille et les dimensions d’une image est souvent de partir du fichier de création et de réduire ses dimensions.
Si vous n’avez pas le fichier d’origine, il est possible de le faire en ligne avec des outils comme :
Le format des images (png, jpg …)
Les formats les plus populaires pour une image sont PNG, JPG & JPEG. Si vous le ne savez pas le principal avantage des fichiers PNG est qu’ils gardent la transparence d’une image. À l’inverse un fichier au format JPG va transformer le vide d’une image par un fond blanc non transparent.
Aujourd’hui le meilleur format pour garder une très bonne qualité d’image et réduire son poids au maximum va être des fichiers en WEBP.
La solution la plus simple pour convertir une image en format webp est de passer par un site tiers comme l’un de ces sites :
La balise alt (texte alternatif)
Les balises alternatives sont des balises qui vont permettre d’indiquer à quoi correspond votre image en y ajoutant un texte descriptif.
Google ne lit pas une image comme nous, les robots la comprennent comme un fichier mais ils ne peuvent pas l’analyser ou le lire comme un œil humain. Il est alors nécessaire de lui apporter plus d’informations complémentaires via le code HTML qui lui est lu.
En plus du nom du fichier lors de votre import, vous pouvez ajouter cette balise ALT qui va permettre de décrire l’image et ainsi améliorer son référencement sur Google Images.
De plus cette balise est utilisée par les personnes en situation de handicap qui utilisent la fonction description audio sur internet.
Pour compléter une balise ALT, il faut décrire votre image en étant concis et précis. Pensez également à ajouter le mot-clé en lien avec votre le contenu de la page ou est présent l’image.
La légende des images
Les légendes ne permettent pas d’apporter une réelle plus-value pour le référencement d’un site. Toutefois, elles sont utiles pour l’expérience utilisateur et permettent de professionnaliser un peu plus un site. Il est courant de mettre les crédits et attributions de l’image dans cette partie.
La page et les textes autour de l’image
Le texte avant et après vos images a son importance pour le référence de vos images sur Google Images. En effet, si l’image positionnée est au sein d’un article sur une thématique dédiée et d’un mot-clé précis. L’image en question aura plus de chance d’être indexée sur cette thématique ou mot-clé.
Car les robots vont lire l’ensemble de la page et comprendre que l’image fait partie de la page et donc qu’il y a un lien avec la thématique de la page.
Détecter les images cassées sur un site
Les images cassées sur un site internet sont aussi un facteur pénalisant pour votre référencement. C’est pour cela qu’il est important de les détecter et de les réparer ou les changer.
Si le site est un WordPress, vous pouvez trouver de nombreuses extensions qui permettent de vérifier que votre site n’a pas d’images ou de liens cassés.
Il existe aussi des outils en ligne qui permettent d’analyser un site pour trouver l’ensemble des liens cassés. Notamment des extensions Google Chrome comme Broken Link Checker.
Les vidéos
Les vidéos sont souvent les éléments les plus lourds et les longs à charger sur un site internet. Il y a deux grandes manières de gérer les vidéos sur un site, d’un côté un hébergement interne et de l’autre un hébergement sur une plateforme extérieure.
Dans le cas d’un hébergement interne, il faudra penser à optimiser votre vidéo pour avoir la plus grande qualité d’image et la taille de fichier le plus faible possible.
C’est notamment le cas si le site utilise des vidéos en background en affichage.
Le format Webp, vu précédemment, peut s’appliquer à une vidéo et donc réduire le poids de votre vidéo en gardant une haute qualité d’image.
Dans le cas d’un hébergement externe comme mettre vos vidéos sur Youtube, Dailymotion…
Ici, on va alors intégrer la vidéo sur le site, ce qui permet d’alléger le chargement de la page de votre site internet. Les optimisations dans ce cas sont minimes car la vidéo n’est pas hébergée sur le site. Le chargement se fait alors via la plateforme d’hébergement.
Les PDF
Bien que n’étant pas des pages d’un site internet, les fichiers au format PDF peuvent être référencés sur les moteurs de recherche. Ils sont même facilement identifiables lors d’une recherche car on voit apparaître une mention PDF en bout de ligne du lien.
Pour qu’ils soient facilement accessibles sur Google quelques règles et optimisations sont à prévoir.
Premièrement, on retrouve deux principaux formats de fichiers PDF. Ceux ou l’on peut sélectionner le texte avec le souris et ceux ou l’on ne peut pas. Les fichiers PDF doivent être du premier cas pour être mieux référencé.
Pour changer cela, il faut voir du côté de la génération du fichier PDF lors de l’export. L’export ne doit pas vous donner un fichier aplati qui ne sera au final qu’une suite d’image. Et comme nous l’avons vu, les textes sur une image sont mal détectés par les robots d’indexation.
Dès lors que le fichier PDF est bien généré, voici quelques optimisations à effectuer.
Le poids du fichier
De la même manière qu’une page web ou une image le poids du fichier a son importance pour le référencement d’un document PDF. Plus il sera léger, plus le temps de chargement sera court.
Vous pouvez dans un premier temps modifier l’export de votre fichier pour optimiser sa compression. Mais il existe aussi des outils en ligne qui permettent de compresser gratuitement votre fichier PDF.
Les balises du fichier
À compléter après avoir utilisé des outils pour compresser vos PDF. Car souvent ces outils en ligne modifient ces informations.
- Titre
- Auteur
- Objet
- Mot-clé
- Sujet
Le nom du fichier
Comme pour une image, le nom qui est donné à un fichier PDF a son importance pour le référencement. Il faut mettre le ou les mots-clés dans le nom et essayer de décrire au mieux le contenu de votre fichier en quelques mots.
Deux éléments à prendre en compte si vous souhaitez référencer des fichiers PDF depuis votre site :
- Le tracking ne fonctionnera pas
Si vous utilisez des solutions de tracking comme Google Analytics sur votre site, les fichiers PDF indexés ne seront pas pris en compte dans les rapports et les analyses. N’étant pas des pages web, les fichiers PDF indexés n’auront pas les scripts de tracking. Vous ne pourrez pas avoir des statistiques classiques d’une page web.
- Attention au duplicate content
Si un document PDF est indexé attention à ce qu’il ne soit pas un extrait ou une simple copie d’articles présents sur votre site. Si cela est le cas, il pourrait être analysé par les robots d’indexation comme du contenu dupliqué.
Lors de votre audit technique SEO pensez bien à analyser ces contenus (images, vidéos & PDF) et de voir s’ils sont tous correctement optimisés en fonction des critères précédemment cités.
11 – Le contenu dupliqué
💡 Dans cette partie : Détecter et corriger les pages et contenus en double pour éviter le contenu dupliqué
Le contenu dupliqué ou duplicate content est une notion que l’on entend souvent quand on s’intéresse au référencement naturel.
Ainsi les robots des moteurs de recherche vont crawler de très nombreux sites et peuvent détecter des pages web très similaires ou identiques à l’intérieur d’un site ou entre plusieurs sites web.
Cette détection de contenu dupliqué est un critère très important pour le référencement des pages d’un site internet. Car les robots et particulièrement ceux de Google ne vont indexer qu’un seul contenu et non pas toutes les pages.
Il est ainsi très important à veiller à ne pas avoir de contenu dupliqué sur son site internet pour que toutes les pages puissent être indexées et accessibles via un moteur de recherche.
On parle de taux de similarité des textes de 80% voir 70% pour être vu comme un contenu dupliqué.
C’est très souvent le cas pour des fiches produit d’un site e-commerce, ce qui contribue à bloquer l’indexation des pages et nuit les ventes de la boutique.
Il existe plusieurs solutions pour détecter et éviter le duplicate content :
La balise canonical
Nous l’avons déjà évoqué dans ce document, cette balise va signaler aux moteurs de recherche qu’une page propose du contenu dupliqué, qui est reprise d’une autre page.
Sur la page originale, vous pouvez mettre dans la balise canonical la même URL que la page publiée.
Ainsi la page originale ou canonique obtiendra elle la visibilité et l’indexation sur les moteurs de recherche.
<link rel="canonical" href="https://..." />
Les opérateurs Google
Un sujet que l’on a aussi déjà traité dans ce document dans le Chapitre 2. Les opérateurs Google peuvent vous permettre de détecter du contenu dupliqué entre plusieurs sites.
Mettre votre recherche Google entre guillemet permet de rechercher le contenu exact de votre recherche sur une autre page. Vous pourrez ainsi savoir si des copier, coller ont été effectué.
Des outils en ligne comme Siteliner
De nombreuses solutions vous permettent d’analyser un site internet et de savoir si le site a des pages ou des contenus dupliqués.
Siteliner vous permet même d’afficher un taux de similarité mais aussi qu’elle partie d’une page ou d’un texte est dupliqué d’une page à une autre.
Des logiciels comme Screaming Frog
Des outils comme Screaming Frog qui sont des crawlers de site internet permettent également d’analyser l’ensemble du contenu d’un site. L’outil propose de calculer un taux de similarité entre vos pages en termes de contenu.
Ce qui vous permet d’identifier rapidement les pages avec trop de contenu similaires entre elles. Donc de les corriger en modifiant le texte ou en utilisant une balise canonical.
12 – Les liens internes
💡 Dans cette partie : Comprendre la notion de lien interne ainsi qu’à celle du mailling interne pour une bonne organisation du site
Ici nous allons définir un lien interne comme un lien qui va relier deux pages d’un même site interne.
Le maillage interne va donc être l’organisation de l’ensemble des liens internes sur un site.
Pourquoi est-il important de bien gérer ses liens internes et plus globalement son maillage interne ?
Les liens internes vont permettre :
- D’avoir une arborescence claire du site pour Google et les visiteurs
- D’aider les robots d’indexation à analyser votre site internet
- D’améliorer le référencement de votre site
- Donner du jus SEO à d’autres pages de votre site
- De simplifier la nvigation de vos visiteurs
- D’encourager les visiteurs à rester sur votre site
- D’obtenir un meilleur taux de rebond
- D’avoir plus de pages vues et lues
- D’augmenter le temps de session par visiteurs
- …
En somme des avantages aussi bien pour votre référencement naturel que pour les visiteurs de votre site.
Voici quelques éléments à comprendre et à prendre en compte pour vérifier ou optimiser vos liens internes et votre maillage interne.
L’arborescence du site
Le mot arborescence fait référence aux ramifications d’un arbre, c’est-à-dire à cette structure qui part d’une base unique qui vient se séparer encore et encore pour former des branches et ainsi un arbre.
Cette idée d’arborescence pour un site internet va être utilisée pour organiser les pages d’un site. Avec la page d’accueil qui va être le tronc de l’arbre puis les branches et les feuilles qui représentent les pages, sous-pages, produits, articles…
De la même façon qu’un arbre est relié à ses branches et ses branches à ses feuilles. Vous devez relier les pages de votre site entre elles dans une structure logique et en prenant en compte le chemin ou l’importance des pages de votre site
Si vous voulez approfondir cette notion vous pouvez vous intéresser “au cocon sémantique”.
Les liens de navigation
Ce sont les liens internes que l’on utilise le plus sur un site internet. Par convention tous les sites internet ont un Header et un Footer. Et c’est dans ces deux éléments que l’on va retrouver les principaux liens qui vont nous permettre de naviguer sur toutes les pages d’un site.
Quelques éléments à vérifier pour le Header
Quand on clique sur le logo, on retourne bien sur la Homepage ;
- Les ancres des liens ne sont pas trop longues (2 à 3 mots max) ;
- Pas plus de 6 liens à l’affichage dans le Header, vous pouvez mettre des sous-menus pour réduire ou mettre plus de liens dans le Header ;
- Si multilingues la présence du switch de langue ;
- Les liens sont facilement cliquables ;
- L’affichage est bien responsive (tablette & mobile) et on peut cliquer facilement sur les liens.
Quelques éléments à vérifier pour le Footer (conseillés)
- La présence du logo du site
- La présence du slogan de l’entreprise
- La présence des principaux liens du site
- La présence du lien vers les mentions légales
- La présence du lien vers la politique de confidentialités
- La présence des liens vers les réseaux sociaux
- La présence des liens pratiques (blog, FAQ, presse, témoignage, recrutement…)
- La présence des liens pour télécharger votre application (Apple Store, Google Play)
- Inscription à la newsletter
Les liens contextuels
Un terme que l’on ne rencontre pas très souvent dans le milieu du SEO. Mais ce que l’on nomme un lien contextuel est un lien texte qui est positionné dans le contenu d’une page. C’est souvent le cas dans les articles de blog. Des liens qui vont vous diriger vers un autre article du site.
Ici, il faut faire attention à l’ancre des liens, c’est-à-dire le texte qui va remplacer l’URL.
Si possible, il faut que le texte du lien comprenne les mots-clés de la page ou de la page vers laquelle vous allez être redirigée. Par exemple éviter dans un article de mettre “cliquez ici” pour accéder à un autre article.
Les fils d’ariane ou breadcrumbs
Un fils d’ariane, que l’on retrouve aussi sous le nom de breadcrumbs, est un chemin de liens que l’on trouve souvent en début de page.
Ils sont souvent utilisés sur les Blog et sur les sites e-commerce comme ces exemples :
- Pour un site e-commerce : Page d’accueil > Vêtements > Homme > Chaussures > Lifestyle
- Pour un blog : Page d’accueil > blog > comptabilité > comment-gerer-sa-comptabilite
Le fil d’Ariane va aider les robots d’indexation à mieux naviguer sur votre site. Ce qui va permettre d’indexer plus rapidement vos nouvelles pages.
C’est aussi un avantage pour la SERP (La page de résultats d’un moteur de recherche) car des moteurs comme Google affiche souvent le fils d’ariane d’une page. Ce qui permet d’être plus visibles sur les résultats de recherche. Le fils d’ariane permet aussi d’améliorer l’expérience utilisateur des visiteurs.
• Augmenter le nombre de pages vues
Le fait de faciliter la navigation entre les pages va naturellement augmenter le nombre de pages vues et donc lues des visiteurs.
• Réduire le taux de rebond
Les liens cassés
Un lien cassé est un lien qui redirige vers une page d’erreur. Cela arrive quand une page du site a été supprimée ou que l’URL d’une page a été modifiée sans avoir effectué de redirection. Pour détecter puis corriger les liens cassés sur un site, il existe plusieurs solutions.
Si le site est sous environnement WordPress, vous pouvez utiliser des extensions qui permettent de scanner l’ensemble du site puis de vous fournir la liste de l’ensemble des liens mais aussi des images cassées sur le site.
Vous pouvez aussi utiliser Screaming Frog pour détecter les liens cassés en suivant ce guide https://www.screamingfrog.co.uk/broken-link-checker/
Enfin il existe de nombreuses solutions en ligne qui vont venir scanner un site pour détecter ces liens cassés. Des solutions payantes comme SEMRush ou Ahref ou gratuite comme https://www.brokenlinkcheck.com/ ou encore https:// validator.w3.org/checklink
13 – Les liens externes
💡 Dans cette partie: Comprendre la notion de lien externe ainsi que le poids que peut avoir un backlink sur ses performances SEO
Définition et explications
Liens externes, liens entrants, liens sortants, liens retours, backlinks autant de termes que vous avez pu entendre qui viennent un peu complexifier votre compréhension et votre analyse.
Faisons un petit point définition :
- Un lien externe : Il s’agit lien qui va relier deux pages de deux sites distincts ;
- Un lien entrant : Il s’agit d’un lien d’un autre site qui redirige vers votre site ;
- Un lien sortant : Il s’agit d’un lien sur votre site qui redirige vers un autre site ;
- Un backlink : Un synonyme de lien entrant ;
- Un lien retour : La traduction française de backlink (très peu utilisée).
Les liens sortants cassés
Pour ce qui des liens sortants, vous devez vérifier qu’il n’y a pas de lien cassé. C’est par exemple le cas quand vous indiquez un lien d’un site externe sur votre site et qu’entre-temps le site externe n’est plus en ligne.
Le site externe est une page en erreur et vous obtenez un lien cassé. De la même manière que les liens internes de nombreux outils permettent de détecter les liens cassés externes sur votre site. Je vous invite à retourner au Chapitre 11 sur la section “Les liens cassés”
L’importance des Backlinks
L’idée ici est de vous donner un large résumé sur le fonctionnement des backlinks et du système de réputation utilisé par Google qui contribue au classement des résultats sur le moteur de recherche.
Comprendre l’importance des Backlinks pour votre référencement
Un backlink est un lien d’un autre site qui redirige vers un autre site. Et chaque backlink n’a pas la même importance ni le même poids.
La popularité ou la réputation est l’un des trois grands piliers pour le référencement avec la technique et le contenu.
Pour juger de la popularité d’un site internet, ce sont principalement les backlinks qui vont être utilisés avec leur nombre et la qualité de ces liens.
Attention un grand nombre de backlinks n’est pas nécessairement un bon signe pour la popularité d’un site. C’est pour cela qu’il faut relier la quantité avec la qualité.
Ainsi une somme de lien que l’on dit de qualité va contribuer à augmenter la confiance que Google envers votre site. Ce qui vous permettra d’atteindre plus simplement les premières positions sur vos mots-clés.
Comment juger de la qualité d’un backlink et plus globalement de la réputation d’un site ?
Les équipes de Google ont développé un algorithme du nom de PageRank. Cet algorithme détermine une note qui se base sur la quantité et la qualité des backlinks entre les sites.
Pour schématiser, plus une page web aura de backlinks plus la page sera jugée comme “populaire” et donc avec une bonne réputation.
De plus, un backlink provenant d’un site lui-même populaire aura un impact beaucoup plus important qu’une somme de “petits” backlinks.
Ce critère de qualité a été ajouté car il aurait été facile de biaiser le système de PageRank en ajoutant de nombreux liens non-naturels pointant vers un site pour augmenter artificiellement sa popularité.
Ce système de PageRank va permettre de donner une note à un site et est l’un des principaux critères pour atteindre les premières positions dans les résultats de recherche. Toutefois Google ne communique plus aucune valeur liée à PageRank.
Pour pallier à ce manque, plusieurs entreprises ont créé leur notation qui permet d’analyser et de comparer la popularité de plusieurs sites.
C’est pour cela que vous avez peut-être entendu parler de Domain Authority (MOZ), Trust Flow (Majestic SEO) ou encore d’Authory Score (SEMRush).
Ces indicateurs vont, par exemple, vous permettre de connaître la popularité de votre site, de vos concurrents ou encore des sites vous ayant attribués un backlink.
Si vous souhaitez en savoir plus sur les backlinks et le système de PageRank voici deux liens intéressants :
- https://developers.google.com/search/docs/advanced/guidelines/link- schemes
- https://fr.wikipedia.org/wiki/PageRank
Comment voir les backlinks du site en audit ?
Lors d’un audit technique, il est intéressant d’analyser le nombre et les principaux backlinks pour le site.
S’il y a trop de “mauvais backlinks” (achats de backlinks, échanges de liens excessifs…) cela peut avoir une incidence négative sur le site et son positionnement SEO. Un audit technique est aussi là pour analyser ces données.
Google, dans ses Guidelines pour Webmaster, parle “d’un effet négatif sur le classement d’un site dans les résultats de recherche” sans indiquer précisément les sanctions possibles.
Il existe plusieurs solutions pour analyser les backlinks d’un site en audit.
En interne et gratuitement, vous pouvez utiliser la Google Search Console. Sur le volet de gauche, vous avez un onglet intitulé “Liens” et dans la partie “Liens Externes” vous avez tous les backlinks et leurs nombres dans “Principaux sites d’origine”.
Sur Google Analytics, vous pouvez aussi observer les backlinks qui vous génèrent le plus de trafic en allant consulter les sources de trafic puis la partie Referral.
Les outils payants en ligne, ils sont nombreux mais je vais vous montrer un exemple avec l’outil SEMRush.
Il suffit d’aller sur SEMRush, de saisir l’URL du site dans Domain Overview et dans la partie Backlinks vous pouvez observer l’ensemble des backlinks du site dont vous avez renseigné l’URL.

Deux notions importantes le DoFollow & Nofollow
Comme pour les images, il est possible de déclarer des attributs sur une balise, c’est-à-dire des liens. Ils existent deux principaux attributs le DoFollow et le NoFollow.
Ces deux attributs permettent de déclarer aux robots d’indexation si vous souhaitez qu’ils suivent ou non le lien que vous avez ajouté dans votre balise.
L’attribut de lien le plus important est le Nofollow, dont voici un exemple :
<a href="https://page-onze.com" rel="nofollow">Page Onze</a>
Il faut déclarer l’attribut NoFollow pour qu’il puisse être lu par les robots d’exploration. S’il n’y a pas d’attribut Nofollow de déclaré, le lien est automatiquement considéré comme du DoFollow.
Un lien avec l’attribut NoFollow ne donnera pas ce que l’on nomme du jus SEO, comme nous avons pu le voir dans la partie sur les backlinks.
C’est pour cela que cet attribut est important dans l’analyse de vos backlinks. S’il est présent, on pourra alors considérer que ce backlink ne contribuera pas à augmenter la réputation et la popularité du site.
Il existe deux grandes situations ou vous pouvez vous poser la question d’appliquer des attributs NoFollow :
- Quand vous laissez la possibilité aux visiteurs de créer du contenu sur votre site. Par exemple, un espace commentaire ou vous ne souhaitez pas que tout le monde vienne mettre un lien vers leur site pour avoir un backlink et donc du jus SEO.
- Quand vous souhaitez citer un site précis mais que vous ne souhaitez pas lui transmettre du jus SEO. Par exemple dans le cas d’un site hostile à votre propre site ou encore un site dont vous ne souhaitez qu’il devienne plus populaire. Le plus simple dans ce cas reste toutefois de ne pas mettre de lien vers ce site.
Desindexer des liens ou désavouer des liens
Cela est vraiment très peu probable que vous ayez besoin de désavouer des liens. Dans de rares situations cela peut être envisageable, par exemple :
- Si vous avez un message de Google sur la Google Search Console vous avertissant d’un problème avec vos liens ;
- Si vous constatez des sites qui ne devraient absolument pas parler de vous ;
- Ou encore si vous constatez un immense spam d’un site avec peu de valeur.
Pour désindexer des liens vous avez deux solutions :
La première est de demander au site, où vous avez constaté des liens à désavouer, de retirer les backlinks qu’ils ont pu produire sur leur site en envoyant un mail.
Si jamais ils ne répondent pas à votre demande vous pouvez toujours demander à Google de désavouer les liens en passant par ce site : https://search.google. com/search-console/disavow-links
Il existe plusieurs solutions et techniques pour obtenir plus de backlinks de qualité mais cela sort du travail d’un audit technique. N’hésitez pas à venir en parler avec moi !
14 – Les versions mobiles et sites responsive
💡 Dans cette partie : Analyser et optimiser les performances d’un site internet sur ces versions mobiles et plus largement les versions responsives
Aujourd’hui, le trafic internet depuis un appareil mobile (Smartphone ou tablette) représente plus de 50% du trafic total dans le monde. Avec cette simple statistique, on comprend rapidement que les versions mobiles d’un site internet ne sont pas à négliger.
Il faut aussi auditer et analyser la version mobile d’un site internet pour faire un audit technique SEO complet.
Comme nous l’avons déjà vu dans le Chapitre 3 des outils comme GTMetrix et PageSpeed Insights permettent d’analyser les performances d’un site. Ils vous proposent également une analyse de la version mobile d’un site.
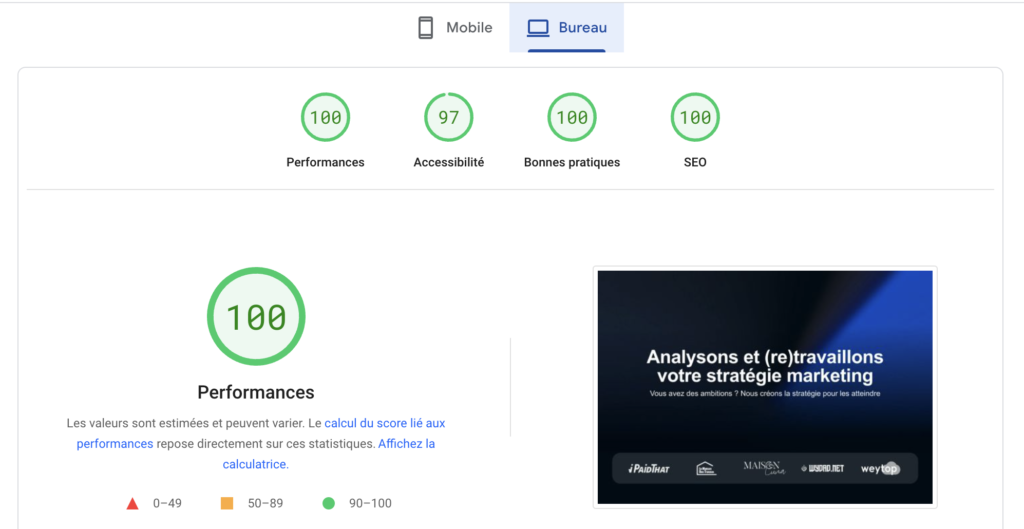
Vous pouvez dans un premier temps utiliser les informations de ces sites pour faire une première analyse de la version mobile du site en audit.
Une fois cela fait, vous pouvez tester si le site est bien responsive. Le plus simple est de directement tester le site en y accédant via votre smartphone et via une tablette. Vous pourrez ainsi noter tous les problèmes que vous rencontrerez lors de la navigation sur le site.
- Est-ce que tous les éléments sont lisibles ?
- Est-ce que tous les éléments sont bien accessibles ?
- Est-ce que tous les éléments sont bien cliquables ?
- …
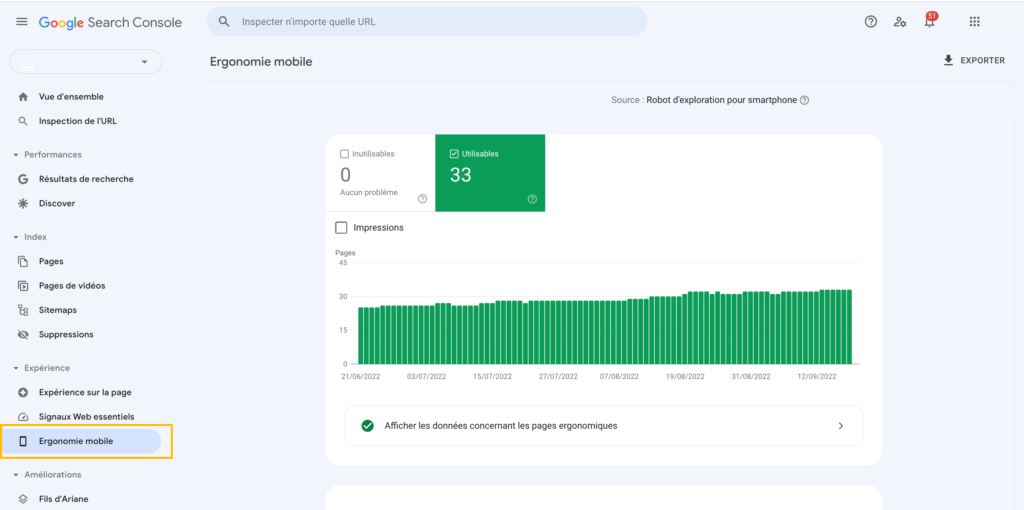
La Google Search Console permet également de faire pour vous une analyse de la version mobile du site en audit. Sur la Google Search Console, sur le volet de gauche vous avez une partie intitulée “Ergonomie Mobile”. Ici vous pourrez voir si Google a constaté des erreurs sur le site qui doivent être corrigées.
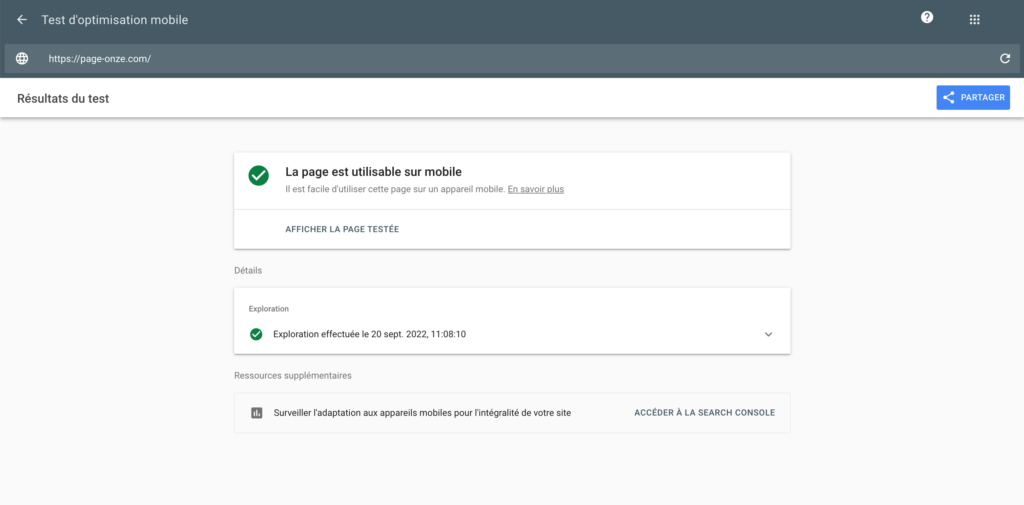
Enfin un dernier outil de Google gratuit pour auditer la version mobile d’un site est le Google Mobile-Friendly Test. Un audit très simple qui vous permet de savoir si une page web est adaptée aux mobiles.
Il suffit de renseigner l’URL de la page que vous souhaitez analyser pour avoir votre réponse.
Si vous souhaitez plus d’informations sur l’indexation et les bonnes pratiques recommandées par Google voici un lien utile : https://developers.google.com/ search/mobile-sites/mobile-first-indexing
15 – Les données structurées
💡 Dans cette partie : Comprendre la notion de données structurées et comment les mettre en place sur son site internet.
Les données structurées sont des informations que l’on va venir ajouter sur un site, via des balises spécifiques, pour mieux décrire le contenu d’une page ou d’un site.
Ces informations sont lues et utilisées par les robots Google pour mieux comprendre le contenu mais elles peuvent aussi être utilisées pour les résultats de recherches à travers les Rich Snippets.
Les Rich Snippets que l’on retrouve aussi sous le nom d’extrait enrichi désignent des informations supplémentaires aux traditionnelles balises Title et Description que l’on va retrouver dans les résultats de recherche.
Voici un exemple :
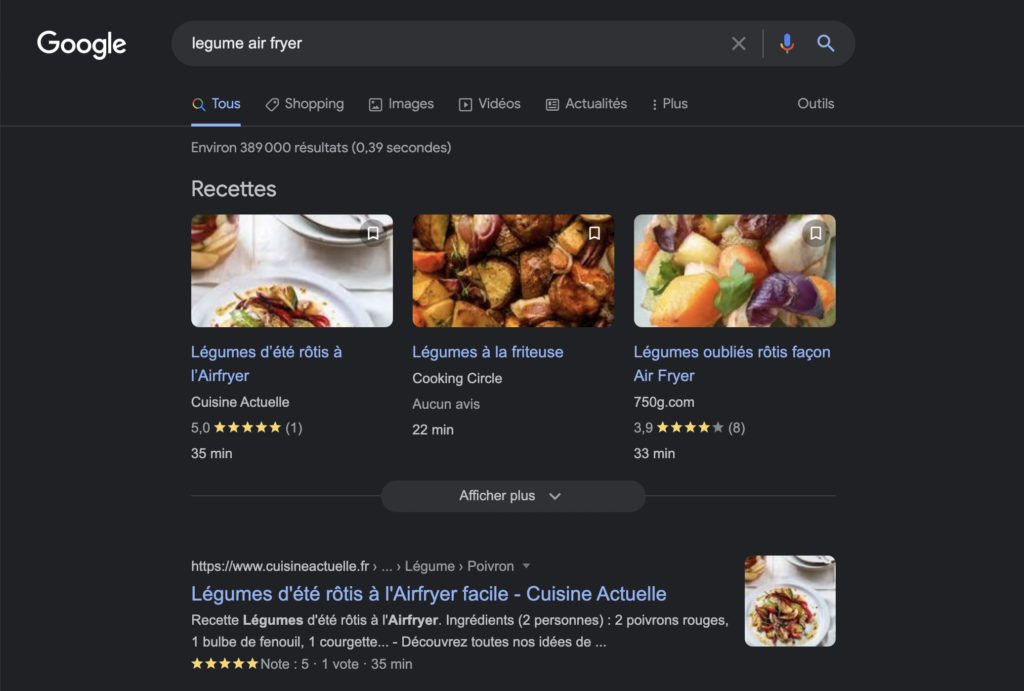
Cela va permettre de se démarquer dans les SERP et augmenter son taux de clics dans les résultats de recherche. En somme, cela va permettre d’améliorer son référencement naturel.
Il existe trois formats qui permettent d’ajouter des données structurées mais aussi d’être lu par Google :
- JSON-LD
- Microdata
- RDFa
Voici un exemple de code en JSON pour l’affichage de données structurées :
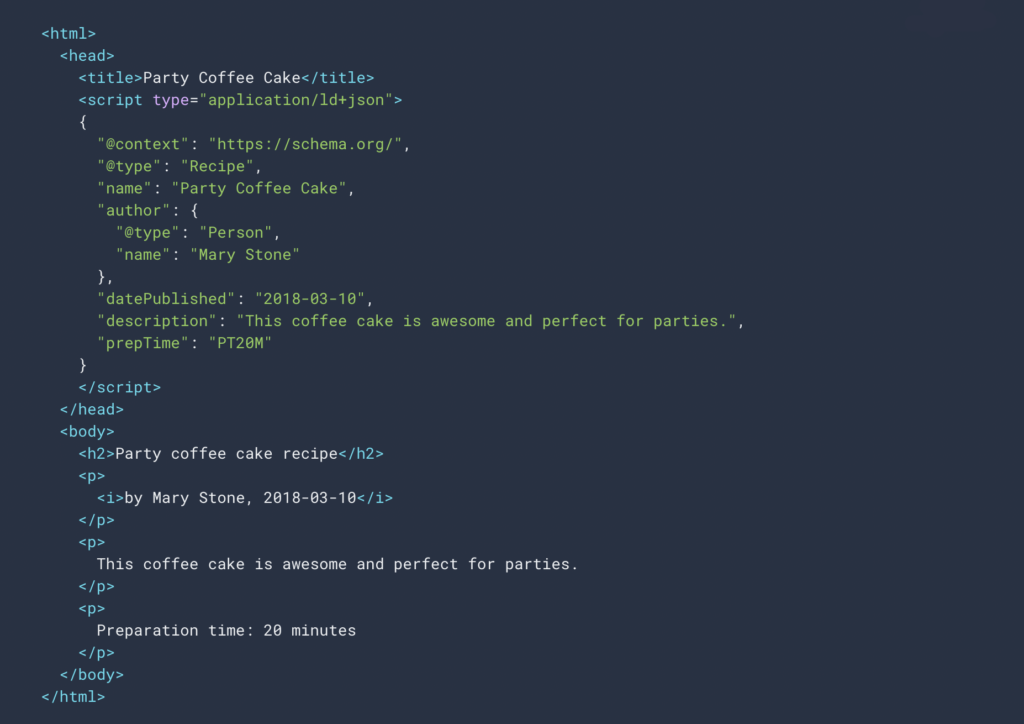
Les informations que l’on peut venir étayer via les données structurées sont vastes et dans de nombreuses catégories.
Par exemple pour un blog et une recette de cuisine vous pouvez préciser :
- Le temps de préparations ;
- Le style de cuisine (française, japonaise…) ;
- Une photo de la recette ;
- Le nombre de calories ;
- Une estimation du prix ;
- …
Vous pouvez retrouver toutes les informations et données que vous pouvez ajouter sur le site de Schema Org https://schema.org/
Selon le site en audit, il peut être intéressant d’analyser les données structurées des pages si elles existent. Et aussi de proposer d’en mettre en place pour améliorer la lecture et le contenu d’un site internet.
C’est un point que l’on oublie facilement lors d’un audit technique SEO mais qui permet d’optimiser les pages de manière très significative pour obtenir plus de trafic SEO.
16 – Analyse des sous-domaines
💡 Dans cette partie : Comprendre la notion de sous-domaine, les trouver, les explorer et les points importants à analyser
Un sous-domaine est une extension d’un domaine. Pour vous donner un exemple google.com est le domaine principal et support.google.com est un sous-domaine de google.com.
Ils sont utilisés pour mieux structurer et organiser toutes les informations qu’une entreprise souhaite mettre en ligne.
Cela permet de gérer différents sites et cela indépendamment du domaine principal. On peut ainsi appliquer simplement des configurations différentes (CMS, Design, Espace, Contenu …) et cela sur un seul hébergement.
De nombreuses entreprises utilisent des sous-domaines pour créer un blog ou pour gérer les versions multilingues de leur site.
Attention, il ne faut pas confondre un sous-domaine, d’un sous-dossier, d’un sous-répertoire. Voici un petit schéma pour mieux comprendre la différence entre ces éléments.


Si un domaine possède des sous-domaines, il faut prendre ces sous-domaines comme de nouveau site. Les configurations peuvent être très différentes et donc l’audit du domaine principal et d’un sous-domaine ne sera pas le même.
Voici quelques questions à vous poser lors d’un audit d’un sous-domaine :
- Existe-t-il un sous-domaine ?
- Existe-t-il plusieurs sous-domaines ?
- Le ou les sous-domaines possèdent-ils un fichier robots.txt ?
- Le ou les sous-domaines possèdent-ils un fichier sitemaps.xml ?
- Le ou les sous-domaines doivent-ils être indexés sur Google ?
- Le ou les sous-domaines sont-ils bien indexés sur Google ?
Puis dès lors que vous avez répondu à ces quelques questions, vous pouvez reprendre le déroulement classique d’un audit de site que l’on va appliquer aux sous-domaines existants. C’est un véritable travail en plus de refaire un audit technique du ou des sous- domaines.
17 – Le tracking du site
💡 Dans cette partie : Observer les différentes possibilités de tracking d’un site ainsi que les outils d’analyse de données
Le système de tracking d’un site fait plus qu’entièrement partie de la gestion d’un site internet. Rares sont aujourd’hui les sites où vous ne trouverez pas un extrait de code dans le code source d’une page.
Ces trackers qui permettent d’avoir et de collecter des informations sur les visiteurs.
Les solutions de tracking sont nombreuses et parmi les principales, nous allons retrouver :
- Google Analytics
- Google Search Console
- Hotjar
- Pixel Facebook
- Tracker LinkedIn
- •…
Dans un audit technique SEO, vous pourrez vérifier s’il existe ou non un ou plusieurs systèmes de tracking sur les pages du site. Le but est simplement de savoir si les trackers sont positionnés sur les bonnes pages et si ils sont bien fonctionnels.
Les UTM (Urchin Tracking Module)
Les paramètres UTM (Urchin Tracking Module) sont des paramètres que l’on peut ajouter aux URL d’une page web. Ils vont permettre d’avoir des informations supplémentaires sur les visiteurs de votre site.
Ainsi si vous avez un code UTM sur une URL que vous mettez par exemple sur une publicité, vous pourrez connaitre précisément d’ou vient le visiteur de votre site.
Voici un exemple d’UTM :
https://page-onze.com/?utm_source=facebook&utm_medium=campagne- 02-22&utm_campaign=produit-1
Comme vous pouvez le voir, il est possible d’ajouter plusieurs paramètres que vous pouvez appliquer à un lien, il en existe 5 : utm_source, utm_medium, utm_ campaign, utm_term, utm_content.
Vous pourrez ainsi retrouver ces variables sur la solution de tracking, on peut par exemple retrouver très simplement les visites depuis un lien avec un UTM source sur Google Analytics.
Pour accéder à ces données sur Google Analytics 4 il faut aller dans :
Rapport -> Acquisition -> Acquistion de trafic (ou Acquisition d’utilisateurs)
Vous pouvez ensuite filtrer les données en fonction du paramètres que vous voulez analyser.
- Source de la session = pour UTM Source
- Support de la session = pour UTM Medium
- Support de la campagne = pour UTM Campaing
(Je vous conseille de mettre Google Analytics en anglais cela sera plus simple pour vos analyses sur cette partie).
Quelques outils pour suivre votre SEO et celui de vos concurrents :
SEMrush, Ahrefs, Ubbersuggest, Google Trends, Google Search Console, Google Key Planner…
18 – Le SEO International
💡 Dans cette partie : Comprendre les bases du référencement naturel pour un site qui souhaite s’internationaliser
Cette partie pourrait faire l’objet d’une documentation entière comme celui-ci. Nous allons cependant voir les points les plus importants à connaître pour développer et auditer un site international et donc disponible en plusieurs langues.
Comme vous l’aurez remarqué, l’ensemble de ce document est destiné à auditer des sites français. Mais comme vous le savez de nombreux sites possèdent plusieurs langues. Et à chaque langue ses spécificités et il en est de même pour le SEO pour chaque pays, chaque langue.
Voici quelques points que vous pouvez analyser rapidement sur un site multilingue :
Le choix pour la division des langues ou des pays
Pour passer à un site multilingue, il y a plusieurs possibilités en ce qui concerne la gestion du et des noms de domaines.
On peut par exemple créer plusieurs sites avec plusieurs extensions de domaine :
- page-onze.fr
- page-onze.us
- page-onze.uk
- …
Il faudra obtenir le nom de domaine pour chacun langue, ce qui est possible mais un peu plus coûteux et difficile surtout si l’un de vos domaines dans une extension spécifique est déjà prise ou utilisée par une autre personne.
Rester sur son nom de domaine principal et créer des sous-domaine ou sous- répertoire pour chaque langue.
- fr.page-onze.com
- us.page-onze.com
- uk.page-onze.com
- …
ou bien
- page-onze.com/fr/
- page-onze.com/us/
- page-onze.com/uk/
- …
Il n’y a pas de mauvaise solution pour la gestion des langues, la gestion en sous répertoire est peut-être plus logique surtout si vous souhaitez faire des langues par pays.
Par exemple avec le Français Suisse, le Français Belge, le Français Canadien, le Français France… Si c’est le cas le système par sous répertoire est à privilégier.
L’important est surtout de vérifier que la structure des langues reste logique en utilisant le même schéma.
L’hébergement de votre site
L’hébergement de votre site en fonction du pays cible ou de la langue a son importance. Aussi bien pour le référencement naturel que pour les performances du site, notamment pour la vitesse de chargement des pages.
Il faut de préférence héberger le site sur une adresse IP locale. Vous pouvez utiliser cet outil pour savoir ou est basé votre site : https://whois.domaintools. com/
La stratégie par langue ou par pays
La grande question à vous poser est de savoir s’il s’agit d’un site vitrine ou d’un site e-commerce. S’il s’agit d’un site vitrine pour présenter votre entreprise vous pouvez rester dans cette logique division par langue. Même si chaque pays a ses spécificités face à une langue.
S’il s’agit d’un site e-commerce pensez plutôt par pays pour un site multilingue. Pour vous donner un exemple qui va vous convaincre, on peut créer un site en anglais. Il pourra répondre à la demande des Etats-Unis et du Royaume-Unis en termes de lecture, toutefois ces deux pays n’ont pas les mêmes devises et les mêmes lois face au commerce.
Il est donc préférable de faire un site pour chaque pays même s’ils usent de l’anglais tous deux.
Plus globalement, on remarque qu’internet est en général plus structuré par pays. Prenons l’exemple des extensions de nom de domaine. Le .fr ne fait pas référence au Français mais à la France. Le .uk pour le Royaume-Uni et pas l’anglais et ainsi de suite.
La balise hreflang
Cette balise est la balise à utiliser sur les pages d’un site pour indiquer la langue de la page mais aussi les autres langues disponibles sur le site.
Voici un exemple de balise hreflang :
<link rel="alternate" href="URL_de_la_page" hreflang="fr"/>
Dans cet exemple, on indique simplement la langue mais on peut également préciser la langue d’un pays spécifique.
<link rel="alternate" href="URL_de_la_page" hreflang="EN-UK"/>
Ici par exemple on déclare que la langue de la page est en Anglais adapté pour le Royaume-Unis.
Si vous souhaitez en savoir plus sur cette balise ainsi que d’autres informations sur comment signaler différentes versions à Google, je vous invite à consulter ce lien : https://developers.google.com/search/docs/advanced/crawling/localized-versions
Google en France mais ailleurs ?
Comme vu en introduction, Google est aujourd’hui le leader mondial des moteurs de recherche. Attention toutefois car dans certains pays Google n’est le numéro ou n’a pas une part de marché aussi forte qu’en France.
D’autres moteurs de recherche existent et ne fonctionnent pas forcément comme Google.
Dès lors que l’on va s’intéresser à un nouveau pays pour son site internet, il faut bien veiller à consulter ces données en amont.
Pour vous donner quelques exemples en Russie Yandex est très populaire, en Chine nous avons Baidu ou encore Naver en Corée du Sud.
Les systèmes de tracking
Un conseil que vous n’êtes pas obligé de suivre mais si une stratégie à long terme est prévue pour l’internationalisation du site internet. Je vous conseille de créer une vue Google Analytics et Google Search Console par pays (ou autres outils de tracking).
Avec le temps, séparer les données par pays vous permettra de vous y retrouver plus simplement dans la gestion de vos données et de mieux comprendre les variations qui peuvent survenir.
Vérifier les liens du sites
Généralement quand on crée une nouvelle langue sur un site, on vient copier puis remplacer les textes pour les traduire un par un. Pensez bien qu’en plus des textes vous avez des liens internes et externes à modifier ou supprimer.
Par exemple, s’il n’y a pas de traduction sur le lien d’un de vos liens externes, vous pouvez penser à le supprimer plutôt que de laisser un lien que votre visiteur ne pourra pas lire.
De la même manière pour les liens internes, il faut veiller à ce qu’une page ne redirige pas vers une autre page du site dans une autre langue au risque de perdre votre visiteur.
Vérifier les changements dans les URL
Pensez bien à changer vos URL et le texte de vos URL pour ne pas laisser les mots dans la langue d’origine.
Vérifier les Meta des pages
Un point que l’on peut facilement oublier, mais pensez à vérifier et changer si nécessaire toutes les balises de vos pages dans la nouvelle langue. Et en priorité les balises Title et Description que l’on retrouvera sur les pages de résultats.
Pour faire simple, tout le contenu d’une page doit être dans une seule et même langue.
SEO et la requête cible en fonction des pays
Attention aux traductions, les termes utilisés dans certains pays sont parfois très différents des nôtres et sont plus complexes à traduire car il n’y a pas ou peu d’équivalents.
Le mieux est de passer par une vraie personne et non par des outils de traduction pour faire les premières traductions ainsi que pour les grands mots- clés et requêtes cibles de votre site internet.
Les spécificités culturelles de chaque pays
Chaque pays a ses spécificités face à une langue mais aussi par rapport à la culture du pays. On peut bien sûr parler du sens de lecture ou encore de l’alphabet mais aussi plus largement des traditions et habitudes des habitants. Attention à ne pas aller contre les spécificités de chaque pays au risque de ne pas passer pour un site sérieux ou professionnel.
Voilà c’est terminé pour ma vision d’un audit technique SEO. Merci d’avoir lu cette page ou seulement quelques chapitres. Si vous avez des questions ou si vous souhaitez travailler avec moi n’hésitez pas à me contacter sur LinkedIn




